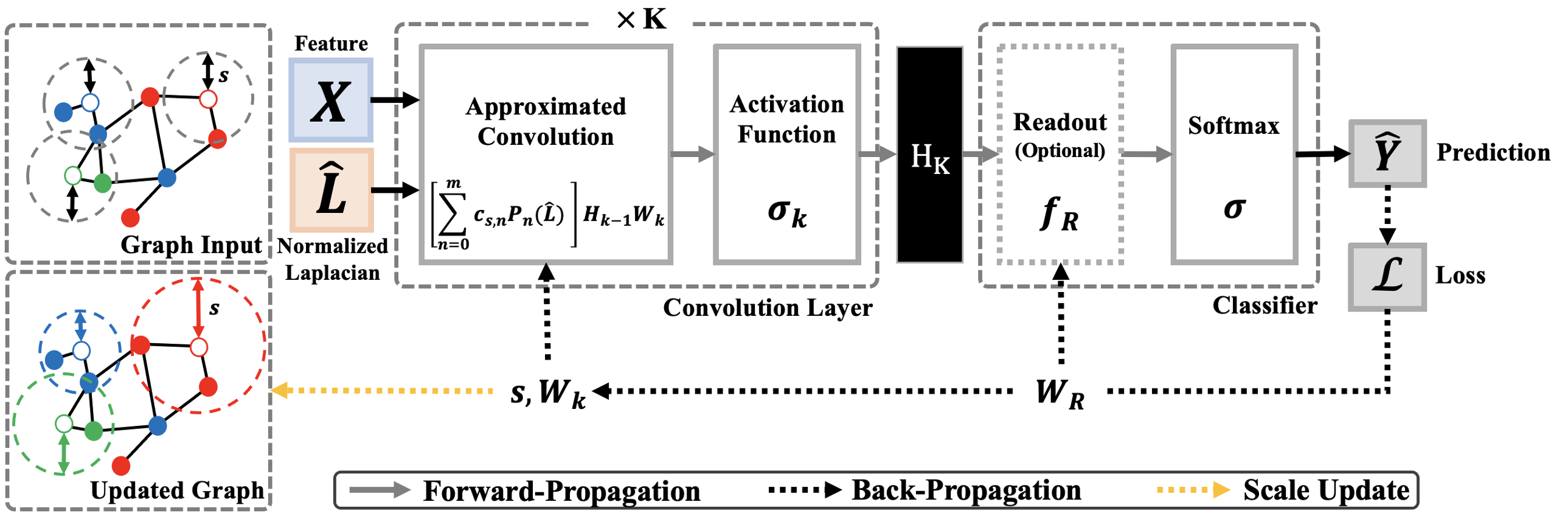
This video shows how LSAP learns adaptive scales on the brain network (graph) for each node
corresponding to a specific ROI during 2000 epochs using ADNI dataset. After training, all
four models can obtain node-wise scales, but the three LSAP models using approximation
are ~10 times faster to learn the scales than Exact under the same conditions.
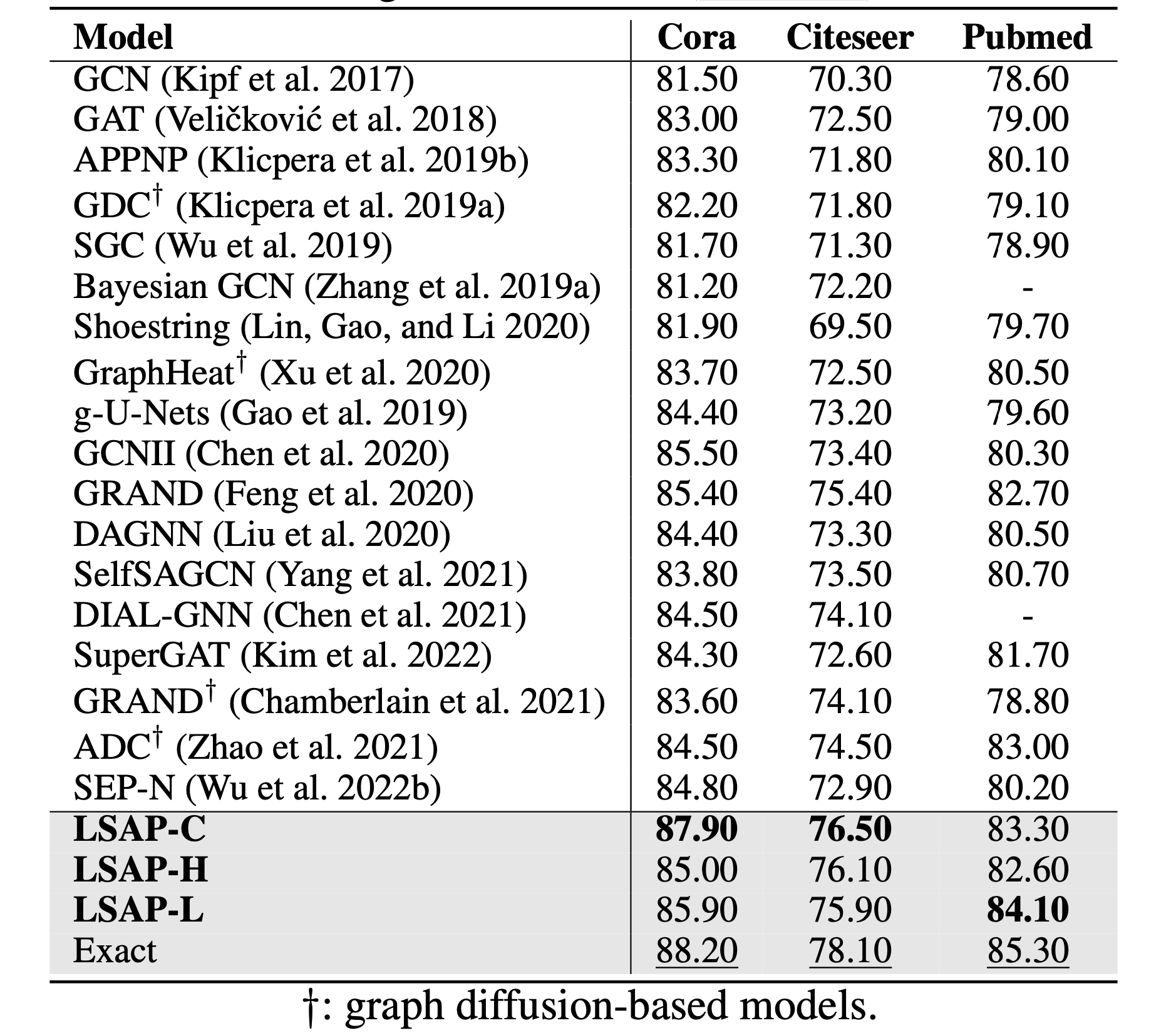
Table: Accuracy (%) on standard benchmarks for node classification. LSAP yields better performances over existing baselines (in bold) similar to Exact achieving the best results (underline).
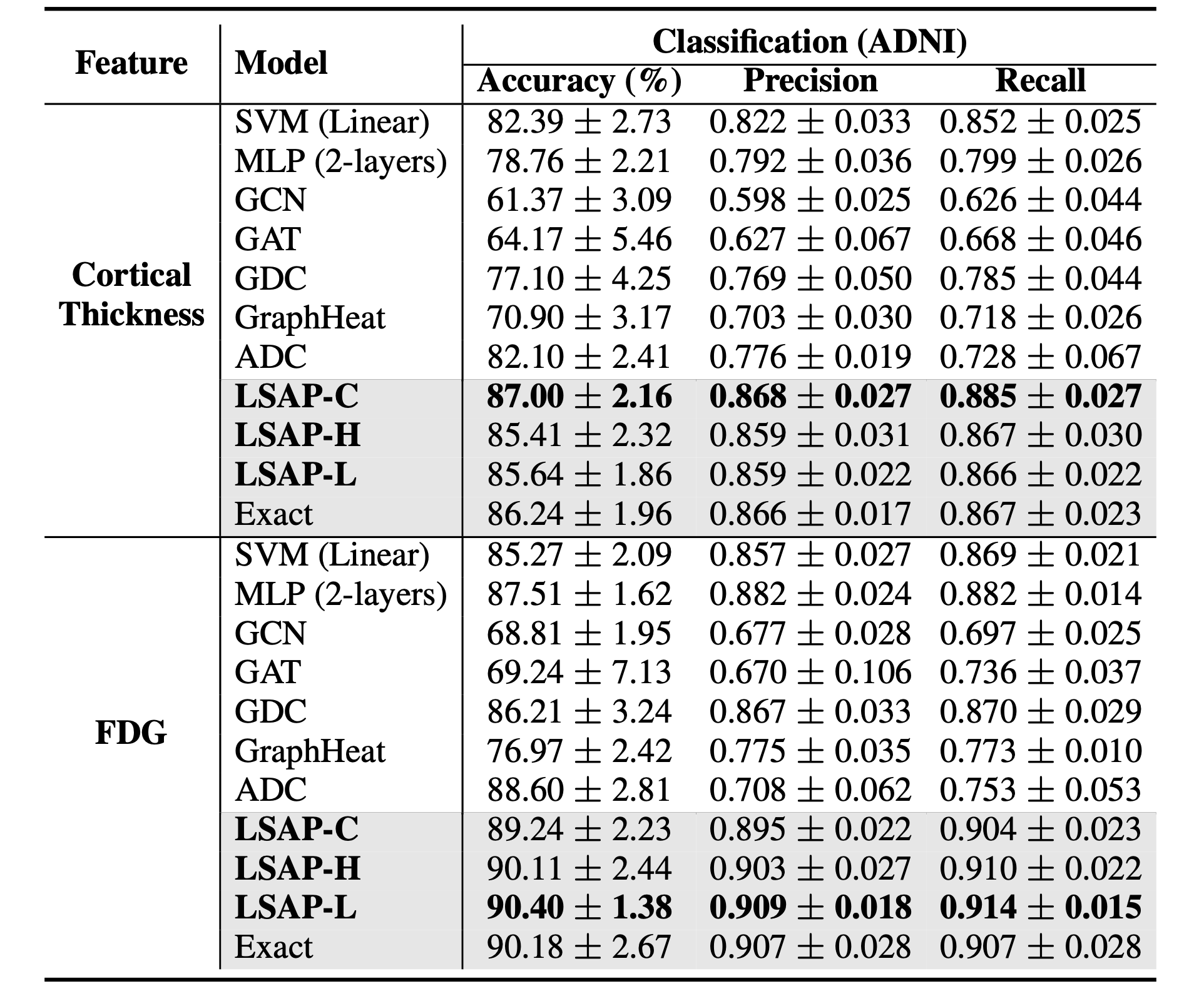
Table: Classification performances on ADNI dataset (for CN / SMC/ EMCI / LMCI / AD).
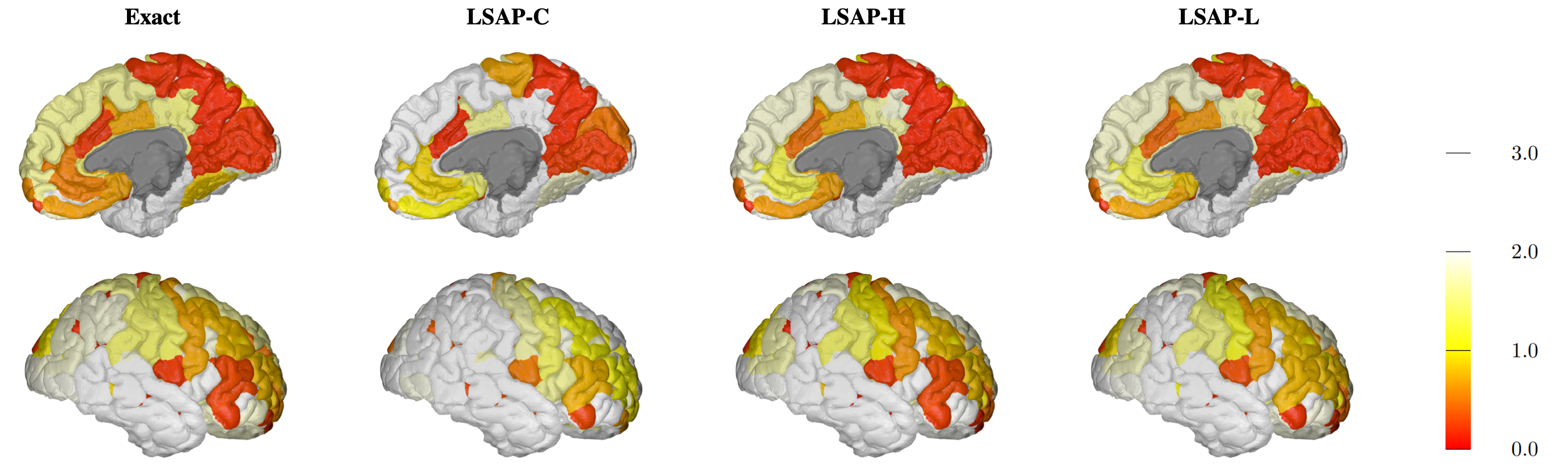
Figure: Visualization of the learned scales on the cortical regions of a brain. This visualization shows the scale of each ROI from the classification result using FDG feature. Top: Inner part of right hemisphere, Bottom: Outer part of right hemisphere.
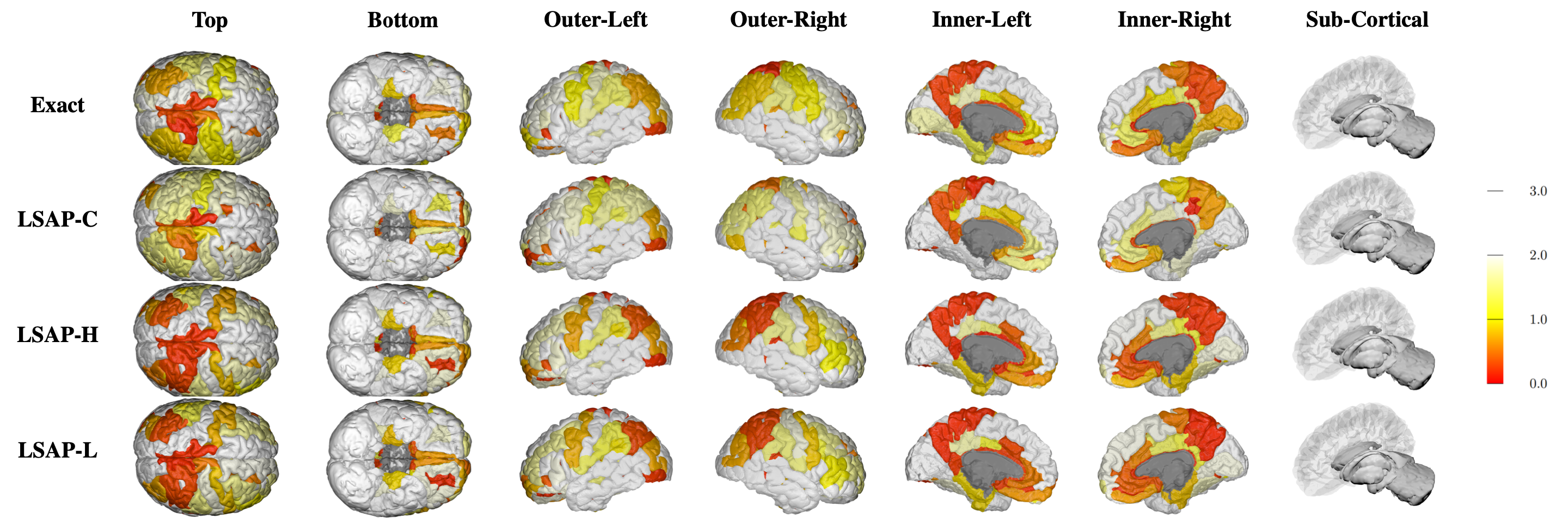
Figure: Visualization of the learned scales on the cortical and sub-cortical regions of a brain. This visualization shows the scale of each ROI through the classification result using Cortical Thickness feature.
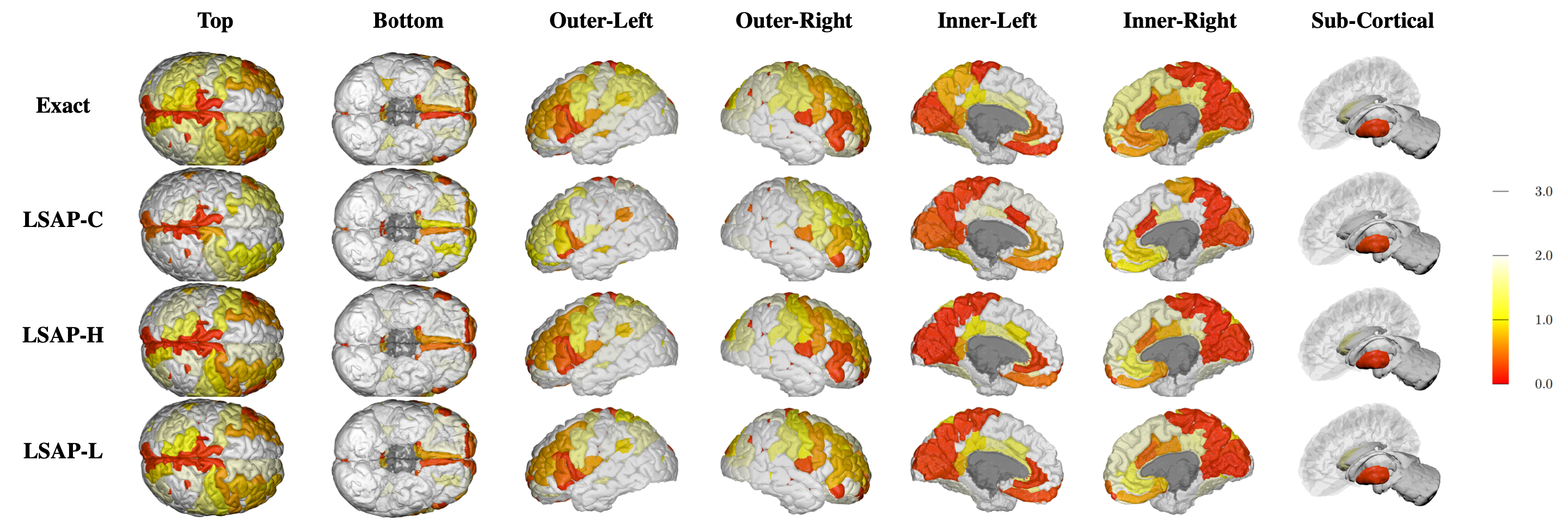
Figure: Visualization of the learned scales on the cortical and sub-cortical regions of a brain. This visualization shows the scale of each ROI through the classification result using FDG feature.
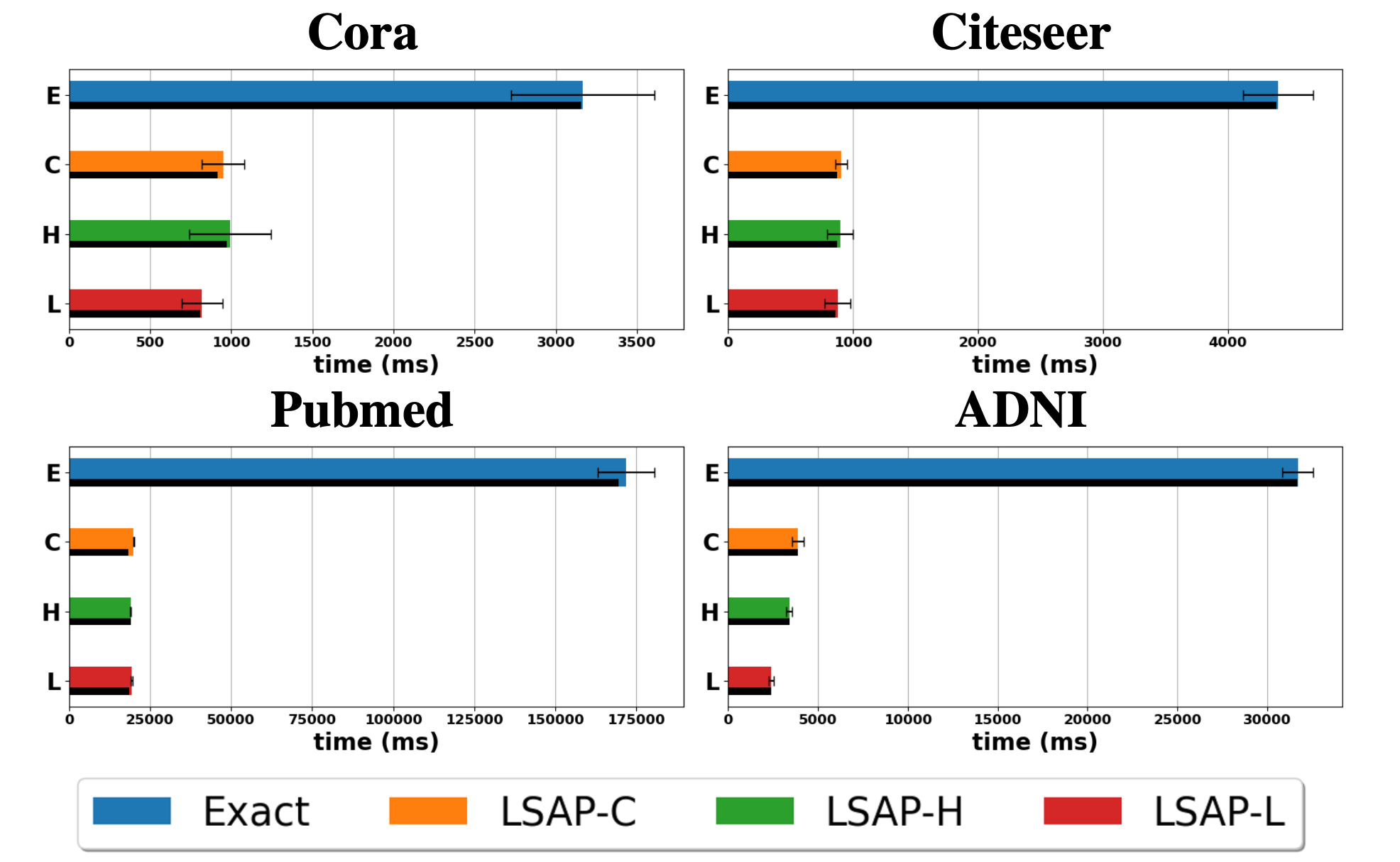
Figure: Comparisons of computation time (in ms) for one epoch (Forward and backpropagation). Within the epoch, time for heat kernel convolution is given in black bar. Results were obtained from node classification and a graph classification with 10 repititions, and LSAP saves majority of the computation.
In this work, we proposed efficient trainable methods to bypass exact computation of spectral kernel convolution that define adaptive ranges of neighbor for each node. We have derived closed-form derivatives on polynomial coefficients to train the scale with conventional backpropagation, and the developed framework LSAP demonstrates SOTA performance on node classification and brain network classification. The brain network analysis provides neuroscientifically interpretable results corroborated by previous AD literature.
@inproceedings{sim2024learning,
title={Learning to Approximate Adaptive Kernel Convolution on Graphs},
author={Sim, Jaeyoon and Jeon, Sooyeon and Choi, InJun and Wu, Guorong and Kim, Won Hwa},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={38},
number={5},
pages={4882--4890},
year={2024}
}